
Oktane19: Building and Running Infrastructure at Scale: How We Do It at Okta
Transcript
Details
John: We're really psyched here to talk to you guys about what we've built at Okta, and Lauren and I are both in the engineering org at Okta, so it's going to be a little bit different than the product talks that you guys might have heard today. Just to kick things off a little, we will make a few forward-looking statements, and this is not a contract that's going to get into product. I'll try to call those places where it's going to happen. I'm happy to give people context afterwards if you have other questions.
John: To frame the conversation, many of you have a company with a number of applications, a number of different personas, right? So here we have our Acme organization with customer apps, partner apps, employee apps, maybe you have others. Maybe you have contractors or other personas that you're building systems for and you have this fundamental problem of identity and access management, and of course this promise that we get with software as a service is that you can decide whether or not this is something that you're going to solve yourselves, offload to a vendor, maybe run yourself, or maybe it's completely not your core competency, maybe it's something you actually think a vendor can do better and together you offer a better product.
John: So you're going to hear from a lot of other talks today about how you can create solutions with the Okta product, and instead what we're going to do is talk to you a little bit about how we think about adopting vendors and the same challenge of what's a core competency to Okta, what are the things that we offload to vendors where we think we can actually create a better service when we do that. We're going to also be talking about how we've built some of our product on top of AWS.
John: We'll frame the conversation through three different lenses: scalability, security, and reliability. And in each, Lauren is going to take you through some stories of day in the life in engineering, the things we do day in and day out to deliver the value and the service that you guys have to come to rely on, and then I'm going to talk through a little bit about how we've architected our solution as well as how we plan to evolve. So with that, I'll hand it off to Lauren to talk about scalability.
Lauren: Great. Thanks, John. So if you're at this session, you probably already know and understand how critical and important scalability is to your infrastructure. Thank you. One of the first things we're going to be talking about today is how Okta has scaled our own infrastructure, and Okta has chose the method of cells as opposed to sharding or a couple of other things. We chose cells as our root to scale our infrastructure. First, what is a cell?
Lauren: A cell is an identical replica of our infrastructure starting from the very bottom layer up to our products and features that we offer. When I started at Okta five and a half years ago we had one test environment, one preview or sandbox environment, and one production environment and, at the time, that was totally fine. We didn't ave that many customers, we were still relatively small, but as we were growing, we were onboarding more customers, we knew that this was going to be very critical to do. Let's talk a little bit about why we chose cell architecture.
Lauren: Well, first and foremost, we wanted to create full isolation. We know that any disruptions that we have, we wanted to keep those as limited and impact the least amount of customers as possible. And one of the other real things that we moved to for cell architecture was we were building on top of AWS, and as you may or may not know AWS offers availability in many regions. We knew as we were growing we wanted to offer customers cells in their home regions as we grew, and you'll see here that we have cells around the world now. We have cells, many in North America, we've got a couple in Europe, and we just recently launched our APAC cell in Sydney.
Lauren: One other quick thing about cells is we knew also that AWS could offer us some other nuances per cell, so things like compliance regulations like HIPAA or FedRAMP, we knew we'd be able to leverage with AWS.
Lauren: Okay. I want to kind of go down into one of our smaller processes that we scaled which is rate limiting process. Now, again many of you are probably familiar with rate limiting. You probably do rate limiting yourselves. We know they provide service protection, performance stability, fairness, and really all of those things are for our customers' benefit, for your benefit. But one thing that we really had to look at was our actual process of how we go about approving rate limit requests. We have a performance team that is dedicated to exactly that, our performance. They would get all of the requests from our customer support teams about customers that were interested in having the rate limits either increased or having for a certain amount time, and our performance team would have to evaluate each and every request. Our QA team would come in, we'd test, make sure that the limit that our customers were requesting our systems would be able to handle the amount of transactions. And, really, we realized that this was a very manual, very taxing, very expensive process. So what did we do to scale our service?
Lauren: Well, we actually created higher rate limits as a product feature within Okta. Now, if you're a large customer, you know that you as a customer or potentially your customer's customers are going to be taking many transactions against Okta's systems, we know that we can provide this higher rate limit threshold to you with no manual intervention needed on behalf of engineering. Now, to scale out a little bit, I'm a technical program manager. I love planning. Even more than planning, I love planning to plan, and so we knew that we were going to have to start capacity planning. What do I mean by capacity planning?
Lauren: Well, we're taking inventory. That means all of our machines. We were looking at key usage stats within our systems. We were looking at things like rate limit requests that were coming in, so our rate limiting capacity. And then we did analysis on it, and these analyses helped us create many things like thresholds, and so while we're capacity planning, our analysis has allowed us to look at things like organic growth that our customers have per cell, do we need to add more inventory and our machines to make sure that our cells are able to handle customer transactions again, do we need to build a new cell, when do we need to start building that new cell, and also do we need to move orgs from cell to cell in order to balance.
Lauren: And, really, these thresholds have helped us in cost savings, and by savings I mean not only monetary savings like when we move from one old infrastructure to a new one. We can check and make sure we're not leaving old machines behind, so we're saving money that way, but really we're saving costs of time and energy and engineers, and we being able to identify manual processes that engineering was able to take and turn them into automated processes. And I'm going to hand it back over to John to talk a little bit about some of those automated processes that we're working on.
John: Thanks, Lauren. Yeah. As Lauren was mentioning we have a lot of environments, and we call them cells. But I'm just curious to make this relevant to all of you. How many of you have at least two environments that you need to deploy your code to in some lockstep fashion, like maybe a test in production environment? Raise them up high and keep them up there. Okay. How many people have three plus environments? Okay. How many people have five plus environments? Okay. So maybe that where we hit the region trade-off where now you're talking about multi-region. Yeah.
John: This problem exists in a lot of organizations. We need to have consistency going out through all of our environments, and it gets harder and harder the more environments you have. And you also have this trade-off where you're trying to ship all the time, you're trying to have velocity. And so we also have these other kind of hidden costs that you run into where maybe if you have a serial deployment through all of those different environments, it actually takes a day or longer to get your code out the door. So there's parallelism that we need to add, and there's also coordination challenges where one team might be trying to get one change out that depends on some infrastructure from another team.
John: And the challenge is that you want to have the ability to point a new artifact at a particular train and have it go out the door without having to go to each environment and run your deployment script. A lot of people are on this journey, and we've been on this journey for a while, this journey where you have an automated deployment, but you still have to go to each environment and kick it off.
John: And so the new abstraction that we've been working on is this concept of release trains, and it's this idea that you can take whatever form of artifact that you have, and you can rely on the fact that it's going to consistently go through every environment in production, and so if one team is working on rolling out a new cell or a new environment, a new region, and yet another set of teams is releasing two new services and five new code updates, they don't need to be all talking in lockstep because you have an automation system in place.
John: And so to go into a little bit more detail, the way we got into this is we started with the ECS runtime, and this was before Amazon had the EKS service or the Kubernetes as a service offering, and this became our model for any microservice at Okta, was to get it containerized in docker and then setup a tool that would be able to apply that change to every environment in production. We call that tool Conductor. And as we've been going we've been seeing that there's other parts of the system that could really benefit from this rigger.
John: I'm just curious. How many of you have Lambda somewhere in your infrastructure today? Okay. And how many of you, keep your hands up, if you have CI and CD for your Lambda? Okay, awesome. And how many of you have that working through every one of your environments so it actually goes on a train? There's no hands up for that part. Yeah. That's a challenge. And that's something that we've been working on and we recently released internally.
John: Another one is Terraform. How many of you are using some form of infrastructure as code? Okay. Yeah, a good number of people. And a lot of people are using this technology for provisioning infrastructure. I talk to a lot of folks who are like, "Yeah, maybe I'll do an update here or there, but mostly it's how I roll out my infrastructure initially." What we're working on now is also creating trains for Terraforms, so that if we're trying to change the underlying version of an Omni and an auto-scaling group or something like that, that that can also go out on a train and have that initial declarative place in source control and then a separate mechanism for rolling it out.
John: And lastly, we recognize that we're going to have some environments that aren't going to be easily containerized, and so we've built our tool to also work with calling out to Ansible and still visiting every environment. We gave a talk on this a few years ago at re:Invent. There's a short link at the bottom. We built our tool using a number of low-level services from Amazon including their simple workflow service, and essentially what we offer up to our developers is a YAML document that they can use to describe the steps of their deployment and that will allow them to add approval steps, allow them to call out for test automation that might have to fully pass before we then go and proceed or otherwise rollback, and now that we've acquired Azuqua we're really excited to look at opportunities to dogfood that product in our workflow model here.
John: The last thing I want to touch on with scalability, we've talked a lot about having cells, and a cell is one really, really big hammer that we can use to stamp out a whole bunch of additional capacity for our customers, and Lauren also mentioned about isolation and regionality that it provides. But as the Okta service has been getting exponentially more requests to the system, we've actually rolled out cells fairly linearly. What's that meant is that over time the capacity of a given cell has continued to meet that demand from customers. And the way we've solved that is by continuing to invest more and more of our workloads in using horizontally scalable infrastructure.
John: If we're getting into a new problem domain that we're still kind of exploring on, we might start with a relational database, we might start with MySQL, proxy SQL for scaling out reads, but if we're noticing that certain access patterns need caching and things like that with Redis, then before GA we'll be pushing on teams to ensure that we can handle the load that we're expecting. Now I'm going to hand it back to Lauren to talk about security.
Lauren: Thank you. Security, everyone wants it, everyone needs it, and really what we're thinking about when we say security and everyone wanting it is that really what that means is you want to buy a service that's secure. You don't want to have to think about anything or have to do a lot in order to make sure that the products and services that you're using are insecure or have to take a lot of action. At Okta, we really go to work for you and make sure that we are keeping up with security standards and best practices, and I'm going to give a couple examples of two things that we've done in the past year and a half where we really have gone to work for you to make sure that we have a very high and secure, reliable service.
Lauren: First is our upgrade from TLS 1.0 to TLS 1.2. Now, like this cat working very hard at his laptop, we felt like we did something similar. We first had to take inventory of all of our products and services that use TLS 1.0. And actually it was surprising. Almost all of our services were using it, so we had to first take inventory, then we needed to make sure that we could upgrade those to make sure they were TLS 1.2 compatible. We QA-ed those very rigorously. So that's one aspect of making sure that we provided the tools that you're already using, things like the LDAP, the AD agent, and make sure that those would be working.
Lauren: And the second part was that we knew that customers would need to take some action, so what did we do? We met with our customer support team, we made sure that there was robust documentation for our customers available, as engineering we met with our customer support team to make sure that they understood and were prepared to help customers make these migrations. And then we actively monitored traffic patterns, and so every morning at 9:00 a.m. myself and a few other people from our Okta team would hand roll customer orgs from old routers that accepted TLS 1.0 to our new routers that only accepted TLS 1.2. This took months and was something that we didn't exactly want to do, but we knew that it was very important to do and we knew, again, we wanted to keep up with industry standards and best practices.
Lauren: The second example I'll share is about Specter and Meltdown. Now, again, you're probably very familiar with these two vulnerabilities. They were a bit deal and, of course, like this cat, we again had stuff that we needed to do. So what did we do? We started out on our edge and made sure that we kernel patched the hundreds of machines on our edge, then we moved to not our edge but our products that contained PII or customer data, made sure that those were patched, and then we moved to on our long tail. And we knew that this was very, very important. Again, your safety and your customers' data is very important to us. We want to make sure that you trust Okta, and so this was a high priority. Our engineers worked very hard on making sure that everything was patched and ready.
Lauren: And so what were the main takeaways of this? Well, basically, one of our main takeaways was that we don't have to put this much effort into this anymore. We want to look like this cat on the right who's napping and relaxing, so I'm going to hand it over to John to talk more about the things that we're doing to improve and make sure once we do have another infrastructure upgrade or another vulnerability, that we'll be able to catnap.
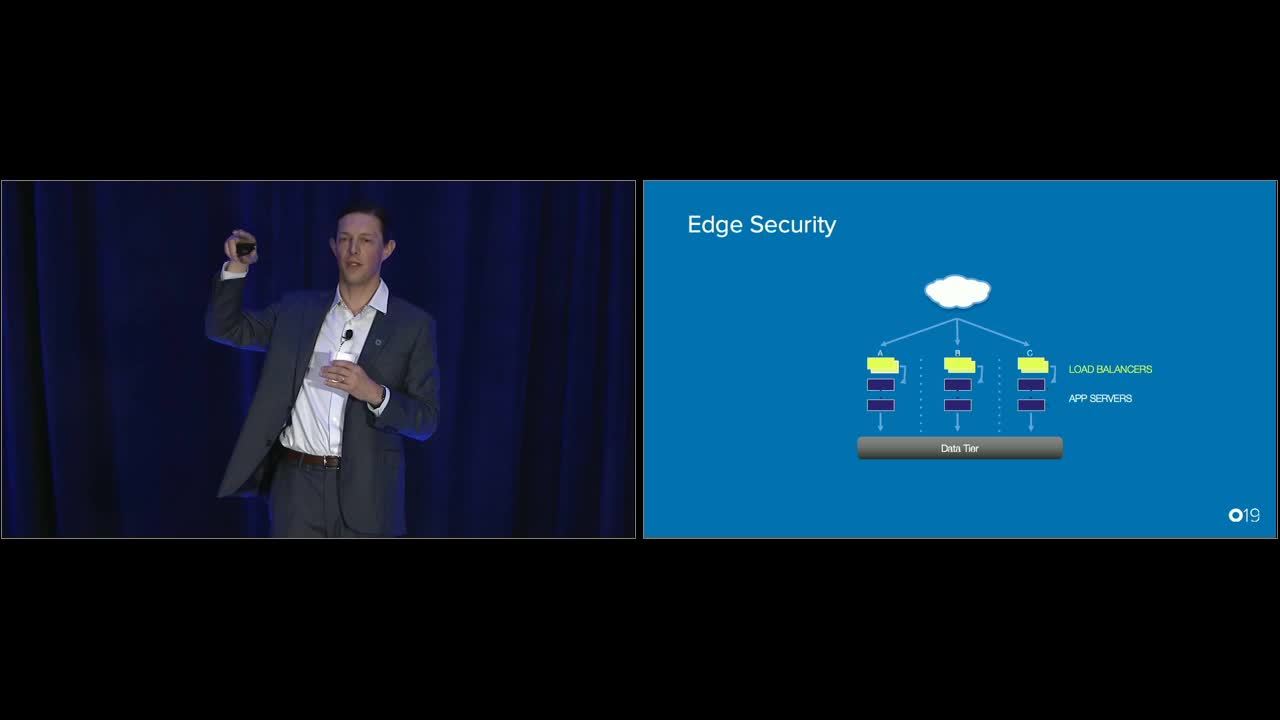
John: Yeah, we definitely could've used a catnap and that massage thing when this came out. As Lauren was mentioning, maintaining edge security in particular is a challenge. Sorry. I'm losing my voice a little bit. And we're always going to work with our customers to ensure that you're getting the upgrades but without interrupting service. That's what that 1.2 rollout story is really all about. It's about ensuring that we work with you guys to get everyone modernized. But as we talk about the edge and we talk about threat insights and the fact that Okta's core competency allows us to really invest in this identity provider that we're building, that you can all leverage, and we get these insights in seeing across a bunch of different customers and attacks that are happening, the thing we're missing visibility on is that same set of attack factors down at the lower levels of the application and Layer 3, 4 network.
John: And AWS is really in the unique position to do that. If you think about this as defense and depth, and you think about this as what is our core competency and what could we actually do a better job for you if we had better visibility, we've started to move towards having the application load bouncer run in front of our product. And this is something that we're in the process of, and the reason for this, again, it's coming back to this idea of what is the core competency, what are the capabilities that we were able to do before. We're not going to change and remove the capabilities that we have, but we wanted to be able to leverage the additional DDoS protection that AWS offers in Advanced Shield as well as the WAF capability where you're now able to protect and fully block traffic before it's even accessing the service. This is a perfect example of one and one make three when it comes to figuring out what our core competency was, figuring out what AWS is going to be investing in, and then marrying those together to give you the most secure edge we possibly can.
John: Also, as Lauren was mentioning, we want things like Meltdown and Specter, there're going to continue to be more vulnerabilities like this. That's just one of a number of issues that will continue to come up, so it's really about the process for how do we make it fast, how do we get low-level kernel updates out to our environment as quickly as possible. And so here the first step has been focusing on getting as much of our infrastructure as possible into the standard auto-scaling group and being able to leverage a model where we can slowly update the underlying Omnis of hosts throughout an auto-scaling group, so going to the first host, doing some testing, this is our canary out in production, looking at our metrics, and then slowly rolling out that new version of the Omni out to the rest of the environment.
John: The challenge with this approach is that when you have many, many applications and many microservices, you have to understand the context in which you're making that Omni upgrade in that particular application because they're tightly coupled to the host. This is where docker and containerization has been a big part of our strategy here because when you're running in containers on top of auto-scaling groups, you can choose to have multiple services running on top of the same host infrastructure and do that same host rollout but not having to know and coordinate with all of the app teams and all of the different ways that they do their deployment because it's up on top in containers and there's a scheduler keeping the right number of machines and containers running for that application.
John: So this has been a big part of our journey and continues to be something that we're investing in. Back to Lauren's point so that we can be that resting cat, and it can be a lot faster to continue to rollout this stuff.
John: Another area that's been important to us is thinking about Zero Trust, and the way I think about Zero Trust there's a lot of marketing around this and if you probably poll the room and get people to tell you what it means, you'd get a lot of different answers. And so we just think of them as some good security principles just like separation of duties or least privilege. And so what we're really thinking about in the context of server access is that we want to get rid of long-lived, static keys. You lose the ability to note that that key is associated with an identity, and you lose some of the policy granularity that you can have when you have shorter-lived, ephemeral keys. It was interesting because as we're thinking about what's our core competency in Okta, we're an access management business and we've been focused on application access, we internally have this problem of how do we lock down and better protect our own infrastructure. Should we go off into this other business are and also do access management for infrastructure?
John: And so as we looked around at the different solutions that were out there, it was pretty key that there were some really ... It was pretty clear that there were some very good solutions, and I'm really psyched to have the ScaleFT team join us and offer the advanced server access product, and we are all also using that internally at Okta. We've been working very hard to be able to dogfood this product to get these additional benefits of continuous authentication, ephemeral keys, and being able to take into context more and more information about the user and the device.
John: And so just to illustrate this, there's a tough FedRAMP requirement. How many of you have to deal with FedRAMP requirements? Got you. Yep. Thanks. Yeah, so there's this tough requirement that to manage and work on workloads where you're potentially accessing the data, you need to be a US citizen on US soil, and so if you think about how are you going to implement that in a model where those people might need to access logs to debug issues, they might need to chat about issues with either the customer or just internally, and they need to access servers, and so where do we get those two required attributes in this process? Can Okta help with that? If you have an HR as master model or you have some source of truth system that can provide you citizenship capability, maybe that confers a group membership inside Okta like the FedRAMP admin group.
John: And then this "on US soil," requirement, how would you do that with a long-lived key? It'd be pretty tricky, right? Because you've handed it out to people, and what's preventing them from maybe using it while they're in a different country? With the Okta sign-on policy, though, what we can do is, and the fact that when you want to go to the server we're always right just in time issuing a short-lived ephemeral certificate. Because of that model, our policy can kick in and evaluate and say, "Are you coming from an IP that's in the US?" I think this is just a really good illustration of a use case we have internally, and I do want to say that this is, in the forward-looking things. Advanced server access is a GA product that's been announced, but the FedRAMP capability's still something that we're working on, so that's still forward-looking.
John: And I'll hand it off to Lauren to talk about reliability.
Lauren: Okay. As many of you may know, one of Okta's mantras is #alwayson. And in order to have an always on service, you need to have a very high level of reliability, so what are some of the things that we're thinking about when we're talking about scaling our infrastructure to make sure that our systems are more reliable? Well, I want to talk about something that engineering, one of our mantras is which is #nomysteries, and #nomysteries was actually coined by our wonderful CTO, Hector Aguilar, and part of #nomysteries is really understanding when we have an incident, what is the real root cause and then identifying the ways in which we can make sure this never happens again.
Lauren: I'm going to share a quick anecdote. One of our cells, a couple of years ago, we were having a lot of incidents with, and we really couldn't figure it out. It was just one cell. We kept debugging. We were trying to tweak our systems, just keep tuning and tuning. We were recording everything down, and finally we realized it was a very small commit made by a developer, so a self-inflicted wound that was very painful, but one of the outcomes of that that we learned is that we really, in order to live #nomysteries, is we really needed to make sure that our logging was better. And we're proactively logging so that way when we do have bugs, we're able to look at those logs and really understand what's going on under the covers and underneath in our systems.
Lauren: One of the ways in which we're building up resiliency, living this no mysteries lifestyle is with a process that we call cops and robbers. Cops and robbers, something similar to Netflix Chaos Monkey where we have our test environment set up, we have our robbers who go in and try to destroy things, and then we have our cops who are monitoring, watching, looking, and assessing how resilient our system really is on different kinds of attacks. When we're thinking about launching a new feature or we're thinking about new tooling that we're rolling out, we always have cops and robbers to ensure that we find all those bugs before you do.
Lauren: And then in the case that we do have incidents which happen, as is life all software has bugs, we really go to work and have root cause analysis. Now, you probably also have something similar where you're trying to find the exact cause of an issue. When we have root cause analysis, we are working with either an isolated team that the bug was on. We will have larger group meetings if it was across a certain spectrum of our product or of our infrastructure, and we gather together, we talk about what the issue was, what the impact of the issue was, was it disruptive to customers, and then also we talk a little bit about how we can make sure that this never happens again. And something that I think is really special at Okta is that we really do care about how to make sure that this never happens again and being more reactive and also proactive at the same time.
Lauren: We've developed a process called engineering urgent, and in our engineering urgent process we have a totally separate backlog that issues that come up during root cause analysis. Yhey're triaged in a way where engineers get time to work on these aside from working on regular deliverables like features, fixing bugs, that kind of thing, and we really make the time and invest the time and set it aside in order to make sure that these issues are triaged, worked on, developed, and iterated on. And John's going to talk a little bit more about how we're doing that at an architecture and infrastructure level.
John: Thanks. Yeah. The term high availability comes up when we talk about reliability, and the way we think about it at Okta is a layered approach because you're probably consuming some low-level infrastructure as a service offerings, but you might also have SAS or Platform as a service. And your ability to control and mitigate the architectures at those different layers really requires kind of a different approach. This is probably the most obvious one for folks. Amazon offers availability zones, and we take an approach where anything that's running on hosts, so that maybe we're running open-source Redis or basically anything that's in our standard lowest level of the infrastructure is going to be across three availability zones, have an active region, and then data's being replicated over to our DR region where we're also across three availability zones.
John: This is kind of the foundational layer, and this is how we start off, but as you move up the stack and you think about platform as a service, you lose a lot of control. Amazon added S3 bucket replication a while back, but bucket replication is really, it's asynchronous and it's only going to be highly available for reads after that asynchronous write makes it over to the other bucket. It's not highly available for writes. Same thing with Kinesis, same thing with a lot of their services, and so we've found that to make our service reliable so that you don't have to be worried about the architecture that we're creating, we end up doing a little bit more work under the covers.
John: For example, in the S3 case we've augmented the AWS SDK to actually do dual writes in the super critical write paths that we have, and do read repairs when you find that an object isn't present. Same thing on Kinesis. Another example is with DNS. We originally used Dyn DNS, and we were in three different regions in Dyn, and who would have thought that Dyn would be the target of a massive DDOS attack that would take down all of those regions? And so we backed up, we're like, "Okay, this is a core problem. We need to solve it for our customers. What are we going to do?" We manage DNS on behalf of all of our customers. We have thousands and thousands of records. We had to take that internally, become the source of truth of information, and then have a mechanism for propagating that to both Dyn and to Route 53 so that we could be multi-provider.
John: Another good example of this is KMS, and if you think about the properties of a key management system, probably the most fundamental thing is that your master keys don't leave the system. That's the whole value of not having to rotate those keys. But then how do you have redundancy if you can't export the key material? And so we gave a talk at re:Invent a few years ago on this topic as well, and we essentially did is we created a key hierarchy. The keys that protect our tenants' data, we have a separate tenant key per tenant, and that key is protected by multiple routes of trust. It's protected by the KMS in the active region, it's protected by a KMS in the DR region, but unlike the earlier model that I was talking about, we actually just run them active active. If our application can't talk to one of the KMS regions, it will fail over to the other region.
John: We also use, in this case, an RSA key where the public key, the key that's used for encrypting new org tenant master keys is online, and the private key is offline and split requiring two people to bring it together in a break-loss scenario. And we did that to avoid vendor lock-in if there were ever a scenario where AWS somehow corrupted the data, lost the keys, worst-case scenarios.
John: These are just a couple examples of how we go above and beyond at the platform as a service layer so that we can really have a good active-active strategy even though the vendor under the covers might not be able to offer that. And, sure enough, right before re:Invent, actually, KMS went down on the East Coast for a while, and so this is an example where no one had to wake up, our encryptions and decryptions that are probably the most important thing that we're doing on behalf of our customers continued to function and otherwise we probably would have had almost an hour and a half of downtime.
John: Another aspect of delivering reliabilities is high quality, and so as we were talking before about the release trains, another aspect of it is that we're increasingly getting confidence as that artifact is shipping out through those environments. And we first do that in the test environment where we have we call synthetic transactions. Synthetic transactions are essentially walking through the system the way a user would walk through the system, and we have a model where every team in the company has identified their critical flows. Those critical flows are running as not just tests, they're not just end-to-end tests that you run in CI. They're also running continuously in every one of our environments. So when we go out and deploy to the first test environment, in addition to having already passed all of the CI, we're now getting a chance to see it fully wired up in an environment that has many, many services all having to work together and talk together, and ensuring that those big end-to-end use cases are still working for customers.
John: And the beauty of that model is that you can take those same tests and use them to know whether or not we're having an issue in one of those cell environments out in production, and we also can use them during the deployment process to further rollout of our code if we're finding issues there. We heavily, heavily use both this concept of synthetic transactions as well as slowly rolling out through the environments. And the last thing I'll say here is just that we also do a bake in the preview environment for a week. That means that all of our customers who have set up test environments where they may already have their own CI or they may already have their own scripts that they're kicking off every week, we're also getting that layer of protection again before the code goes out to production, and of course we have the ability to control the order in which we deploy the different environments in production to have the risks spread out over time.
John: Another big investment area that we've talked about in past events is how we've built out CI system. At a certain point we got to a level of scale where we needed to back off of some of the open source tools and more heavily invest ourselves in a containerized-based CI environment. I know you can't see it in that graph there, but I think this is probably two and half or three years old, so I imagine that graph is going up to many hundreds of containers all running at the same time to run topic-build tests. I imagine that number is significantly higher at this point, but the point is that we put a ton of effort into running all of the tests for topic branches prior to check-in so that we don't have this scale of problem of who broke the build, who caused the latest set of test failures.
John: Another area of investment is feature flags, and this is just the ability to basically turn code on and off. And we use this both to mitigate a risk of just something that might be going out in a single release where maybe we want to have a very quick turnaround where we wouldn't have to do it even a hot fix, but we'll basically wrap that functionality in a feature flag that'll get pulled out the second it's good. Or we'll use them more long-lived for things that are going to go through our beta EA and GA lifecycle, and that's our model for getting feedback from our customers, again, iteratively over time until we know that it's going to scale and meet your needs.
John: The last thing is when we're making infrastructure-level changes, sometimes we need to leverage blue, green, or canary-style deployments where we'll have a small subset of machines that have, say, the new version of the patched kernel or something like that where it's hard to reason about the interaction issues that you might have, say, with the JVM and the kernel until you get a big enough workload on there where you can see the variables and the tuning that you might need to make.
John: In conclusion, we've talked about scalability, we've talked about how Okta's investing in horizontally scalable infrastructure to make individual cells scale indefinitely; we've talked about how we invested and continue to invest a lot in our tooling and automation around how we get deployments out the door and how we create this concept of trains for the organization; we talked about how we're dogfooding the new server access product on our vision to adopting these Zero Trust principles; we talked about how we live this #nomysteries mantra to get to the root of every issue and really make sure that we're allocating the right amount of time to solidifying our product before moving on even if that includes writing new tools, adding new analysis, that kind of stuff so that we can solve those problems quicker the next time they come up.
John: I'm sure a lot of you have heard the term, "It's turtles all the way down." I think it's pretty relevant to this talk because you're thinking about architecting your work. And for maybe the folks who don't know this, there's the mythology, there's a number of mythologies that believe that the world is carried on the back of either an elephant or a big turtle, and then someone of course poses the question, "What is that turtle riding on?" And the answer is it's turtles all the way down. We're all building technology on top of other layers of technology, and I couldn't put all the turtles there, but I think you get the point. We hope that in this talk you got to understand a little bit more of the layers below us, how we think about architecting on top of it, and in turn, gaining a little bit of trust in how our process works at Okta and how we've built the system that you've come to know and use.
John: We have about five minutes left for questions, and we'd love to get feedback from folks. We love talking about this stuff. We love learning what you guys are up to. I think we're going to have some mike runners in the back, and we'll take some questions. And, yeah, the mikes will be coming up.
Speaker 3: How are you doing? Good presentation. Thank you. I just want to clarify something. You talked about advanced server access and FedRAMP. Was that a hint at sort of things to come potentially for that?
John: Yeah. Internally, Okta itself, we have to figure out how we're going to address FedRAMP, and that's what I was talking about. That was an internal story of how Okta is going to solve our FedRAMP problem. I realize that there's a separate concern which is when will that product be available for folks who are also trying to solve the FedRAMP problem, and I can't answer that question, but I can say that clearly we're starting down this path internally on a dogfood project so it's going to be a little bit of time. But I'm sure there'll be some announcement when we do break ground on that.
Speaker 3: Okay.
Speaker 4: Hi. My question is regarding the cells. Do you have complete partitioning or sharding of data between cells or each cell itself has global data of all the customers?
Lauren: Yeah. We thought about sharding, and our cell architecture's actually completely isolated. There's no sharding at all. It's the complete stack in each cell.
John: Totally shared nothing.
Lauren: Yeah. Nothing's shared.
Speaker 4: Not even customer data or nothing?
John: Yeah. Cells are shared nothing.
Lauren: Yeah.
John: Yeah.
Speaker 5: Hey guys, just wondering ... Could you actually share the names of the products you're using for your synthetic transactions, your CI/CD pipeline, anything like that? Just curious.
John: Yeah. It's kind of moving over time, actually, because there's a number of vendors that offer tools where you go into a UI and run Scope or Ghost Inspector for UI drivers, but I think we're shifting away from those because there's a few challenges. One, it's how do you declaratively define that test, and maybe your test should change in lockstep with the code that's going out. And so how do you do that in a vendor where essentially there's just a single UI, maybe not even an API to provision and change in a Terraform declaration. We do have an internal way that we can run and create jobs in the system, and that tool can launch containers to do whatever, but those containers can run Selenium tests or whatever drivers we want to walk those paths.
Speaker 6: Hey guys. My question is more about as we get customers who may be pumping a lot of data and especially maybe using our APIs. We have rate limits in place, fine. For some, we have increased the rate limits to accommodate the load, but I'd like to know what's the anatomy behind the scenes, per se. Are we kind of doing auto-scaling or the typical buzzwords that come across when talking about AWS infrastructure? And if not, then how are we accommodating big enterprise customers who will be coming in and pumping more and more data whether it be user creation and so on?
John: Yeah. The way I think Lauren was talking about capacity planning earlier, and so it's there's a service protection element, but there's also a capacity planning element. You'll see this even with AWS. One of the easiest ways to have a huge outage in your system even if you've done all the stuff we did with KMS is have a new service overuse your KMS limits and get rate limited by KMS. We've seen that happen. A new microservice didn't have a good caching model and blows out our rate limits. What I'm saying is we understand this challenge that you have, and all these vendors including Okta are going to have rate limits in place even if you're like AWS where it's literally pay for as much as you ... And their model is like, "Please, just give us more money."
John: Our approach on that, though, is we have the limits in place so that we can understand when there are going to be scale changes to the system as well, and I think what Lauren was getting at was that we're creating a better, more automated pipeline for being able to get that feedback and then capacity plan accordingly.
Speaker 6: Thank you.
John: All right, and we've got just 15 seconds left so maybe one last question and then we'll wrap it up. Or not ... All right. Thank you so much, everyone.
This talk will dive into how Okta delivers a secure, scalable and reliable service built on AWS. We'll cover lessons from the trenches and concrete patterns for anyone delivering mission critical functionality on modern cloud infrastructure.